
この記事では競艇(ボートレース)の公式サイトからダウンロードできるテキストデータから欲しい情報を抜き取る方法を解説します。
次のような悩みをもつ人にオススメの内容となっています。
- 競艇のデータ分析がやりたい
- テキストデータから必要なデータを抽出する方法が知りたい
- コードを書く流れが知りたい
最終的なコードだけ見てもわかりづらいと思う人のために、実際どのような流れでコードを書いていったのかも書きました。
特にプログラミング初心者の人には読んでいただきたいですね。
テキストファイルを読み込む
競艇公式サイト(https://www.boatrace.jp/owpc/pc/extra/data/download.html)からダウンロードしたテキストファイルを読み込みます。
今回は2021年9月1日の番組表(出走表)を使ってみたいと思います。
同じファイルを使いたい場合は下のリンクからどうぞ。
Google Colaboratoryでファイル読み込みをするには以下の手順が必要です。
- GoogleDriveにファイルをアップロード
- Google ColaboratoryでGoogleDriveをマウントする
- Google Colaboratoryでファイルを読み込む
順に説明しますね。
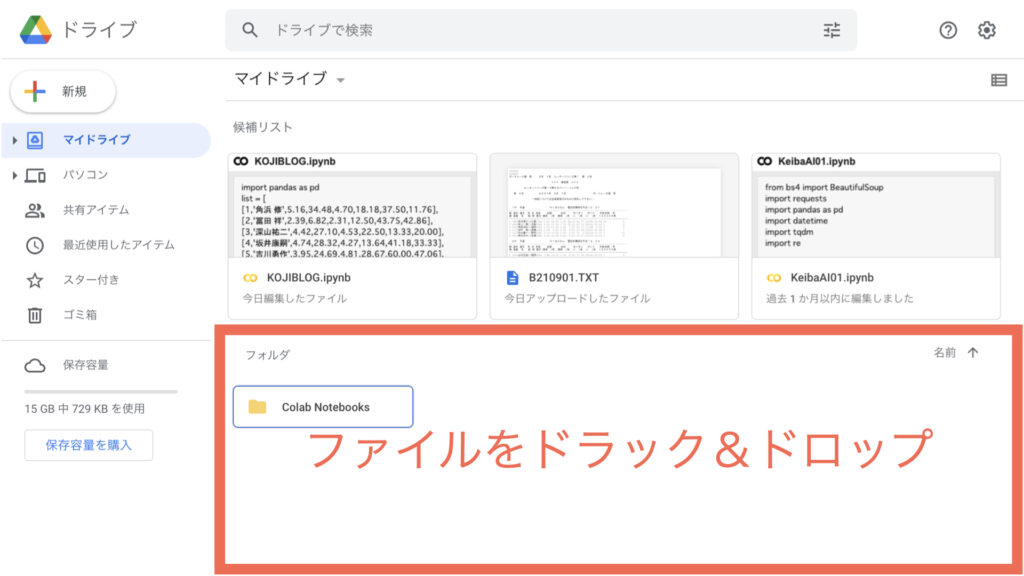
GoogleDriveにファイルをアップロード
Google Colaboratoryでファイルを読み込むには、まず読み込みたいファイルをGoogleDriveにアップロードする必要があります。
Google ColaboratoryにログインしているGoogleアカウントと同じアカウントでGoogleDriveにログインしましょう。
トップ画面で「フォルダ」と書かれているところに、読み込みたいファイルをドラック&ドロップしたらアップロードできます。
Google ColaboratoryでGoogleDriveをマウント
Google ColaboratoryでGoogleDriveをマウントすれば、GoogleDriveに保存されたファイルをGoogle Colaboratoryによって読み込むことができるってわけですね。
マウントと聞くとむずかしそうですが、クリックのみでカンタンにできます。
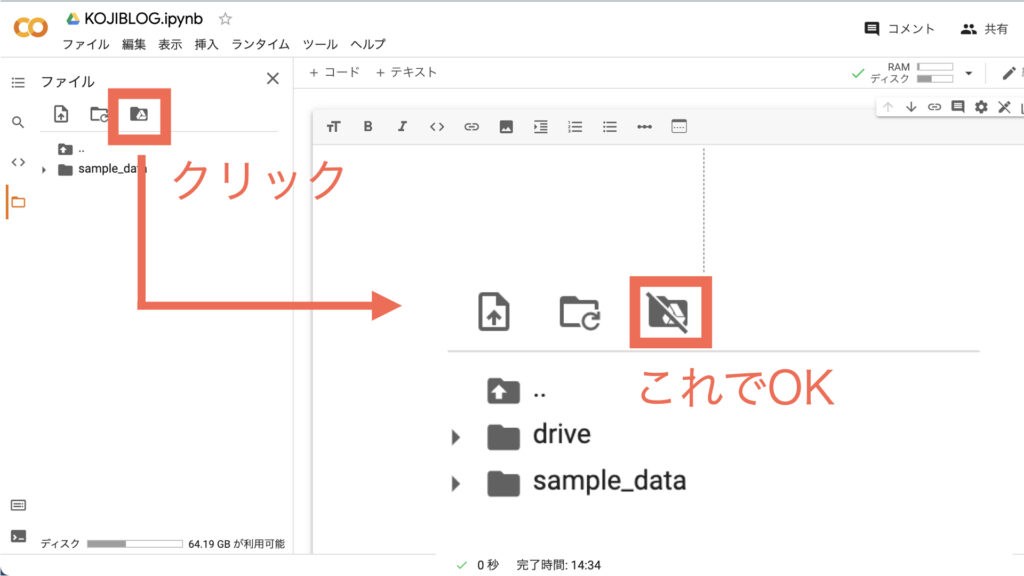
フォルダアイコンに斜線が入り、「drive」というフォルダができていればマウント完了です。
Google Colaboratoryでファイルを読み込む
いよいよGoogleDriveにアップロードしたファイルをGoogle Colaboratoryで読み込むところです。
結論から言うと、たったこれだけのコードでできてしまいます。
with open('/content/drive/MyDrive/B210901.TXT') as f:
data = f.readlines()with openによって指定したパスでファイルを開き、readlinesで1行ずつデータを取り出してdataに入れます。
GoogleDriveに保存されたファイルのパスは「/content/drive/MyDrive/ファイル名」とかけます。
画像で見たほうがイメージしやすいですね。
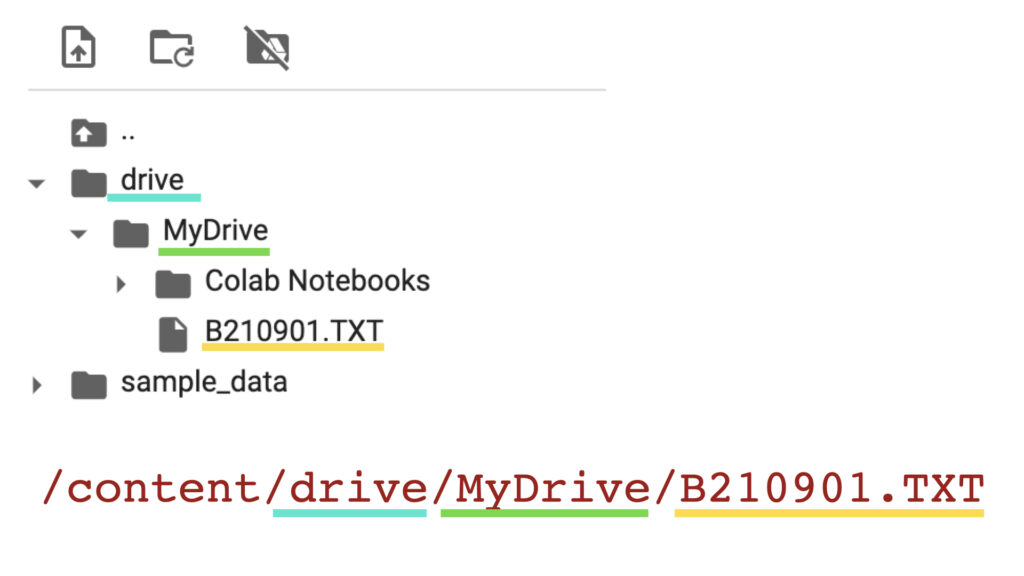
パスはファイルの位置情報のことで、「日本にある東京都の葛飾区に住んでいる田中さん」なら「日本/東京都/葛飾区/田中さん」みたいなイメージです。
さきほどのファイル読み込みコードを実行するとエラーが出ました。
UnicodeDecodeError: 'utf-8' codec can't decode byte 0x83 in position 16: invalid start byte
ファイルを開くときのエンコードがダメだったみたいですね。
「utf-8」じゃなくて「shift-jis」で読み込んでみましょう。
with open('/content/drive/MyDrive/B210901.TXT', encoding='shift-jis') as f:
data = f.readlines()これでうまくいきました。
ファイルを読み込むときのエンコードは「encoding=’エンコード名’」で指定できます。
dataの中身はこんな感じです。
data[:26] --> 'STARTB\n', '22BBGN\n', 'ボートレース福\u3000岡 \u30009月\u30001日 ルーキーシリーズ第1 第\u30002日\n', '\n', ' ***\u3000番組表\u3000***\n', '\n', ' ルーキーシリーズ第14戦スカパー!・JLC杯\u3000\u3000\u3000\n', '\n', ' 第\u30002日 2021年\u30009月\u30001日 ボートレース福\u3000岡\n', '\n', ' −内容については主催者発行のものと照合して下さい−\n', '\n', '\n', '\u30001R 予選\u3000\u3000\u3000\u3000 H1800m 電話投票締切予定12:27 \n', '-------------------------------------------------------------------------------\n', '艇 選手 選手 年 支 体級 全国 当地 モーター ボート 今節成績 早\n', '番 登番 名 齢 部 重別 勝率 2率 勝率 2率 NO 2率 NO 2率 123456見\n', '-------------------------------------------------------------------------------\n', '1 4926吉川貴仁28三重51A2 5.40 34.13 5.33 38.10 24 57.14158 42.86 56 5\n', '2 4826井上一輝27大阪50A1 6.51 51.59 7.75 70.00 47 31.58132 50.00 1 9\n', '3 5041荒牧凪沙22福岡51B1 3.55 15.96 2.85 7.35 22 11.11168 0.00 5 8\n', '4 5172田村\u3000慶20徳島51B1 2.49 6.25 0.00 0.00 67 60.00156 42.86 6 7\n', '5 5110杉山喜一21静岡50B1 3.10 10.00 0.00 0.00 72 0.00124 27.27 3 10\n', '6 5014梶山涼斗23佐賀53B1 4.32 22.99 0.00 0.00 33 27.27133 10.00 3 6\n', '\n', '\u30002R 予選\u3000\u3000\u3000\u3000 H1800m 電話投票締切予定12:53 \n',
テキストファイルを読み込めたので、ここから必要なデータを取得していきましょう。
テキストデータから必要なデータを取得する
データのリストdataから必要なデータをとっていきます。
次の流れでデータを取得していきます。
- 出走表の部分を取得
- 「艇番」から「ボート2連率」までのデータを取得
- データフレームに入れる
図でみるとイメージしやすいですよね。

①で出走表部分のデータを取得し、②でそのデータから必要なものだけを選んでいく形です。
順に説明します。
出走表の部分を取得
出走表とは「どの艇にどの選手が出場するのか」が書いてある部分ですね。
データを取得する部分をいま一度確認してみましょう。
-------------------------------------------------------------------------------\n' 艇 選手 選手 年 支 体級 全国 当地 モーター ボート 今節成績 早\n' 番 登番 名 齢 部 重別 勝率 2率 勝率 2率 NO 2率 NO 2率 123456見\n' -------------------------------------------------------------------------------\n' 1 4926吉川貴仁28三重51A2 5.40 34.13 5.33 38.10 24 57.14158 42.86 56 5\n' 2 4826井上一輝27大阪50A1 6.51 51.59 7.75 70.00 47 31.58132 50.00 1 9\n' 3 5041荒牧凪沙22福岡51B1 3.55 15.96 2.85 7.35 22 11.11168 0.00 5 8\n' 4 5172田村\u3000慶20徳島51B1 2.49 6.25 0.00 0.00 67 60.00156 42.86 6 7\n' 5 5110杉山喜一21静岡50B1 3.10 10.00 0.00 0.00 72 0.00124 27.27 3 10\n' 6 5014梶山涼斗23佐賀53B1 4.32 22.99 0.00 0.00 33 27.27133 10.00 3 6\n'
データをみると、欲しい部分は「行が1から6で始まり、その数字のあとに1つの空白があること」がわかりました。
「〇〇で始まり」ということなのでstartswithを使って条件式をつくりたいと思います。。
racers = []
for row in data:
if row.startswith('1 '):
racers.append(row)for文でdataから1行ずつ取り出し(row)、「1 」から始まっているrowをracersリストに追加しています。
同じ作業を「1 」から「6 」まで行えば、出走表のデータが取れるってわけですね。
やってみましょう。
racers = []
for row in data:
if row.startswith('1 ') or row.startswith('2 ') or row.startswith('3 ') or row.startswith('4 ') or row.startswith('5 ') or row.startswith('6 ') :
racers.append(row)racersリストに必要なデータが入りました。
しかし、問題があります。
コードが見づらい笑
力づくで取り出した感が出まくり。
調べたところ正規表現を使うとシンプルに書けるそうです。
正規表現を使うためにreをインポートし、matchを使って正規表現にマッチしているデータをリストに加えてみましょう。
import re
racers = []
for row in data:
if re.match('^[1-6]\s', row):
racers.append(row)なんということでしょう。
とてもシンプルになりました。
正規表現である ‘ ^[1-6]\s ‘ の部分はこのようにわけて考えてください。
| 文字 | 説明 |
|---|---|
| ^ | 次の文字が行の先頭である |
| [1-6] | 1から6までの数字 |
| \s | 空白文字 |
この3つを組み合わせると
「行の先頭が1から6で始まり、次に空白がある」
となります。
正規表現はとても便利なのでオススメです。
僕もはじめて正規表現を見たときは「むずかしそう、ムリ…」と思いましたが、使ってくうちに慣れてきました。
さらに僕は気付きました。
「このパターンならリスト内包表記で書けるんじゃないか?」
このパターンとは
for文で取り出したデータを新しいリストに入れるとき
という意味です。
そこでリスト内包表記にしつつ
- \u3000(全角スペース)
- \n(改行)
がいらないので、ついでにreplaceで削除しちゃいます。
import re
racers = [row.replace('\u3000','').replace('\n','') for row in data if re.match('^[1-6]\s', row)]うん、良い感じですね。
リスト内包表記にするとコードがスッキリするだけでなく、処理スピードが速くなるそうなので使えるときは積極的につかってみてください。
リスト内包表記で作成したデータracersの中身を見てみるとこんな感じです。
racers[:12] --> ['1 4926吉川貴仁28三重51A2 5.40 34.13 5.33 38.10 24 57.14158 42.86 56 5', '2 4826井上一輝27大阪50A1 6.51 51.59 7.75 70.00 47 31.58132 50.00 1 9', '3 5041荒牧凪沙22福岡51B1 3.55 15.96 2.85 7.35 22 11.11168 0.00 5 8', '4 5172田村慶20徳島51B1 2.49 6.25 0.00 0.00 67 60.00156 42.86 6 7', '5 5110杉山喜一21静岡50B1 3.10 10.00 0.00 0.00 72 0.00124 27.27 3 10', '6 5014梶山涼斗23佐賀53B1 4.32 22.99 0.00 0.00 33 27.27133 10.00 3 6', '1 5053山口広樹25福岡55B1 3.88 15.29 1.56 0.00 17 50.00140 45.45 5 9', '2 4939宮之原輝23東京50A1 6.80 53.03 5.58 41.67 41 42.86142 10.00 21 10', '3 5016宮田龍馬23兵庫52B1 4.47 23.42 5.82 54.55 36 50.00117 18.18 1 6', '4 4960黒野元基25愛知51A2 6.26 45.83 5.87 51.28 51 10.00159 42.86 2 12', '5 4906鈴木雅希26東京54B1 5.43 35.92 3.81 12.50 64 27.27151 50.00 2S ', '6 5015高橋竜矢23広島52A2 5.45 33.90 5.24 36.84 38 0.00120 27.27 3 11']
このデータからさらに細かいデータをとっていきます。
「艇番」から「ボート2連率」までのデータを取得
「艇番」から「ボート2連率」まで13種類のデータを取り出します。
パッと見たとき、データとデータの間に空白があるので、splitが使えそうです。
for s in data:
print(s.split())出力:
['1', '4926吉川貴仁28三重51A2', '5.40', '34.13', '5.33', '38.10', '24', '57.14158', '42.86', '56', '5'] ['2', '4826井上一輝27大阪50A1', '6.51', '51.59', '7.75', '70.00', '47', '31.58132', '50.00', '1', '9'] ['3', '5041荒牧凪沙22福岡51B1', '3.55', '15.96', '2.85', '7.35', '22', '11.11168', '0.00', '5', '8'] ['4', '5172田村', '慶20徳島51B1', '2.49', '6.25', '0.00', '0.00', '67', '60.00156', '42.86', '6', '7'] ['5', '5110杉山喜一21静岡50B1', '3.10', '10.00', '0.00', '0.00', '72', '0.00124', '27.27', '3', '10'] ['6', '5014梶山涼斗23佐賀53B1', '4.32', '22.99', '0.00', '0.00', '33', '27.27133', '10.00', '3', '6']
しかし、splitを使ってデータを分割すると上のようになってしまいました。
選手登番から級別までが1つのカタマリになってしまったり、ボート番号とボート2連率がカタマリになる場合があったりと、データとして安定していません。
(赤字部分がデータとして使いづらいところ)
そこで2度目の登場、正規表現でいきたいと思います。
さきほどと同じmatchが使えるんです。
pattern = '^([1-6])\s(\d{4})([^0-9]+)'
pattern_re = re.compile(pattern)
values = []
for racer in racers:
value = re.match(pattern_re, racer).groups()
values.append(value)values[:10]
-->
[('1', '4926', '吉川貴仁'),
('2', '4826', '井上一輝'),
('3', '5041', '荒牧凪沙'),
('4', '5172', '田村慶'),
('5', '5110', '杉山喜一'),
('6', '5014', '梶山涼斗'),
('1', '5053', '山口広樹'),
('2', '4939', '宮之原輝'),
('3', '5016', '宮田龍馬'),
('4', '4960', '黒野元基')]
re.match(正規表現, 文字列).groups()とすると、正規表現にマッチした部分をタプルで返します。
タプルはリストの友達のようなもの。
取り出したい部分の正規表現をカッコで囲うことがポイントです。
正規表現のところが長くなりそうなので、patternに入れた文字列をre.compileで正規表現パターンに変換しました。
この正規表現パターンをどうするかがとてもメンドウで、トライアンドエラーの連続でしたね。
最終的にpatternはこのようになりました。
pattern = '^([1-6])\s(\d{4})([^0-9]+)(\d{2})([^0-9]+)(\d{2})([AB]\d{1})\s(\d{1}.\d{2})\s*(\d+.\d{2})\s(\d{1}.\d{2})\s*(\d+.\d{2})\s+\d+\s+(\d+.\d{2})\s*\d+\s+(\d+.\d{2})'すごいことになっている笑
それぞれの正規表現がどのデータをとろうしているのか、表にまとめました。
| 正規表現 | 説明 | データの種類 | 例 |
|---|---|---|---|
| [1-6] | 1から6までの数字 | 艇番 | 1 |
| \d{4} | 4ケタの数字 | 選手登番 | 4926 |
| [^0-9]+ | 数字以外が1文字以上 | 選手名 | 吉川貴仁 |
| \d{2} | 2ケタの数字 | 年齢 | 28 |
| [^0-9]+ | 数字以外が1文字以上 | 支部 | 三重 |
| \d{2} | 2ケタの数字 | 体重 | 51 |
| [AB]\d{1} | AかBのあとに数字1文字 | 級別 | A2 |
| \d{1}.\d{2} | 数字1文字 . 数字2文字 | 全国勝率 | 5.40 |
| \d+.\d{2} | 数字1文字以上 . 数字2文字 | 全国2連率 | 34.13 |
| \d{1}.\d{2} | 数字1文字 . 数字2文字 | 当地勝率 | 5.33 |
| \d+.\d{2} | 数字1文字以上 . 数字2文字 | 当地2連率 | 38.10 |
| \d+.\d{2} | 数字1文字以上 . 数字2文字 | モーター2連率 | 57.14 |
| \d+.\d{2} | 数字1文字以上 . 数字2文字 | ボート2連率 | 42.86 |
これだけ見ても「なんのこっちゃ」って感じですよね。
正規表現は見るより使って慣れるのがイチバンかと。
そして僕はまた気付きました。
「このパターンならリスト内包表記で書けるんじゃないか?」(しつこい笑)
リスト内包表記に書き換えるとこんな感じです。
pattern = '^([1-6])\s(\d{4})([^0-9]+)(\d{2})([^0-9]+)(\d{2})([AB]\d{1})\s(\d{1}.\d{2})\s*(\d+.\d{2})\s(\d{1}.\d{2})\s*(\d+.\d{2})\s+\d+\s+(\d+.\d{2})\s*\d+\s+(\d+.\d{2})'
pattern_re = re.compile(pattern)
values = [re.match(pattern_re, racer).groups() for racer in racers]これでようやくテキストファイルから必要なデータを取り出すことができました。
データフレームに入れる
最後に取り出したデータvaluesをデータフレームに入れていきましょう。
pandasライブラリをインポートしてデータフレームをつくっていきます。
import pandas as pd
column = ['艇番', '選手登番', '選手名', '年齢', '支部', '体重', '級別', '全国勝率', '全国2連率', '当地勝率', '当地2連率', 'モーター2連率', 'ボート2連率']
df = pd.DataFrame(values, columns=column)これで完成です。
データフレーム内を確認してみましょう。
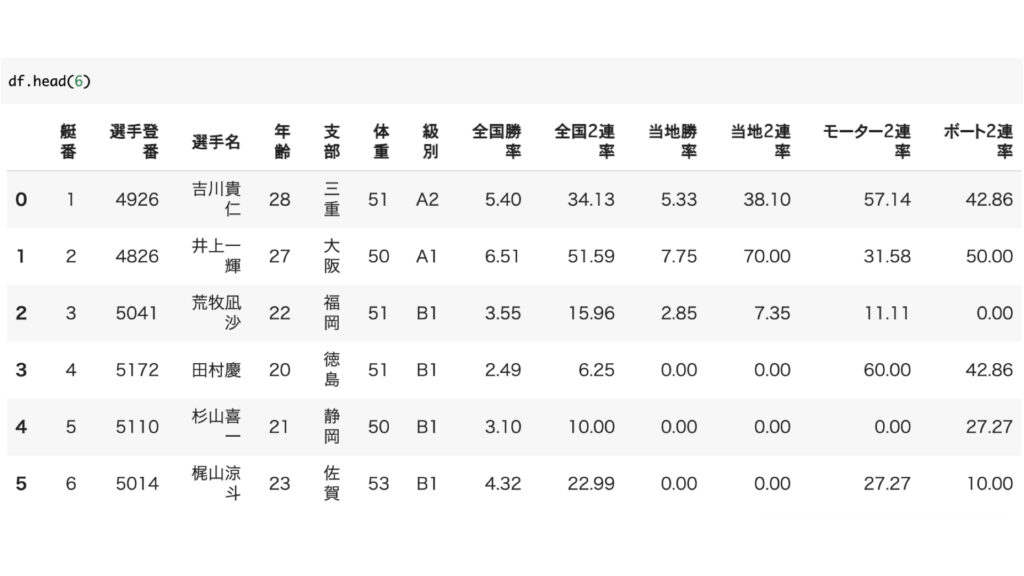
ちゃんと狙ったデータが入っていますね。
すべての作業をまとめたコードも貼っておきます。
よければコピペして試してみてくださいね。
import re
import pandas as pd
#テキストファイルを読み込む
with open('/content/drive/MyDrive/B210901.TXT', encoding='shift-jis') as f:
data = f.readlines()
#出走表を取り出す
racers = [row.replace('\u3000','').replace('\n','') for row in data if re.match('^[1-6]\s', row)]
#必要な13種類のデータを取り出す
pattern = '^([1-6])\s(\d{4})([^0-9]+)(\d{2})([^0-9]+)(\d{2})([AB]\d{1})\s(\d{1}.\d{2})\s*(\d+.\d{2})\s(\d{1}.\d{2})\s*(\d+.\d{2})\s+\d+\s+(\d+.\d{2})\s*\d+\s+(\d+.\d{2})'
pattern_re = re.compile(pattern)
values = [re.match(pattern_re, racer).groups() for racer in racers]
#取り出したデータをデータフレームに入れる
column = ['艇番', '選手登番', '選手名', '年齢', '支部', '体重', '級別', '全国勝率', '全国2連率', '当地勝率', '当地2連率', 'モーター2連率', 'ボート2連率']
df = pd.DataFrame(values,columns=column)こうやって取得した競艇データを利用し、機械学習して回収率を計算した記事を載せておきます。
面白い結果となっていますので、ぜひ読んでみてください。

まとめ
今回は競艇の公式サイトからダウンロードしたテキストファイルから必要なデータを取得し、データフレームに入れる方法を解説しました。
実際のコードを、しかも書いた流れつきで説明したので、初心者の人にはイメージしやすい内容になったかと思います。
文字列から欲しい文字を探すときに正規表現が使えるようになると、取得できるデータの幅がかなり変わるでしょう。
僕もまだまだですが、ぜひ一緒に学んでいきましょう。
ではまた。


コメント