
これまで、Pythonをつかって競馬の機械学習にチャレンジしてきました。

競馬の機械学習を終えた僕は考えました。
「競馬でできるなら競艇(ボートレース)でもできるんじゃね?」と。
ということで競艇で機械学習して回収率を出してみました。
さきに言っておきますが、競艇は競馬よりも回収率が高かったです。
- 機械学習の流れが知りたい
- 競艇(ボートレース)で機械学習したらどのくらい当たるのか知りたい
- lightGBMの使い方が知りたい
このような疑問をもっている人にオススメの記事となっています。
今回、行った機械学習
今回は、機械学習のなかで教師あり学習の分類をしてみました。
使用した機械学習手法はLightGBMです。
LightGBMはデータサイエンティストや機械学習エンジニアが参加するコンペの上位者のなかでかなり使われているアルゴリズムで、しかも初心者でもカンタンに使えます。
学習に必要なスピードが速いなどのメリットもあり、個人的にお気に入りです。
教師あり学習は正解をあたえるのですが、今回あたえる正解は「着順」です。
| 着順 | 目的変数 |
|---|---|
| 1着 or 2着 | 0 |
| 3着 or 4着 | 1 |
| 5着 or 6着 | 2 |
表を見てもらえればイメージしやすいかと思います。
このように正解が3つ以上ある「分類」のことを多クラス分類とも呼ぶそうです。
おおまかな機械学習の流れは「データセットの準備→機械学習でモデルを作成→精度を評価」なのですが、もうすこし具体的に説明するとこうなります。
- データ収集
- データの前処理
- 機械学習でモデル作成
- モデルでレースを予想し、回収率を計算
4ステップの作業をするためにPythonファイルを3つ作りました。
| Pythonファイル名 | 役割 |
|---|---|
| create_model.py | データ収集、データ前処理、機械学習でモデル作成 |
| inspection.py | データ収集、データ前処理、オッズデータ収集、モデルから回収率計算 |
| mymodule.py | 3つの関数を定義「データ収集」「データ前処理」「オッズデータ収集」 |
機械学習から検証までに「データ収集」や「データの前処理」という作業は何度か出てきます。
そのたびに作業部分をコピペしたり書き直すのがメンドウなので、別ファイルに関数として定義しました。
他のファイルで「mymodule.py」をインポートすれば、いつでも関数(作業をパックしたもの)を呼び出せるので便利です。
データ収集
競艇レースデータは公式サイトからダウンロードしたテキストファイルを使いました。
ダウンロード元:https://www.boatrace.jp/owpc/pc/extra/data/download.html
ページ内の「番組表ダウンロード」と「競争成績ダウンロード」からテキストファイルをダウンロードしてください。
ファイル名は「B210801.TXT」「K210801.TXT」となっていて、それぞれ出走表とレース結果がかかれています。
| サイト表記 | ファイル名(例) | 中身 |
| 番組表ダウンロード | B210801.TXT | 2021年8月1日の出走表 |
| 競争成績ダウンロード | K210801.TXT | 2021年8月1日のレース結果(オッズつき) |
出走表データ(B)と結果データ(K)からそれぞれ次のデータを抽出しました。
| テキストファイル | 項目 | |
| 出走表データ(B)から取得 | 艇番 年齢 支部 体重 級別 全国勝率 全国2連率 当地勝率 当地2連率 モーター2連率 ボート2連率 会場 | |
| 結果データ(K)から取得 | 着 選手名 展示タイム 天候 風向 風量 波 | |
| 両データから取得 | 選手登番 レースID |
レースIDは日付と会場、何レース目かを合わせて自作してます。
例:2021年8月1日、大村(会場コード:24)の1レース目
→ レースID = 202108012401
出走表データ(B)と結果データ(K)から取り出したデータ数が同じであるとは限りません。
当日に中止となったレースがあるからです。
そこで2つのデータを結合するときに「選手登番」と「レースID」をキーにしました。
data_merge = pd.merge(data_B,data_K,on=['選手登番','レースID'])つまり「選手登番とレースIDが同じときに結合するよ」ってことです。

データの前処理
機械学習をするために2種類の前処理をしました。
- カテゴリ変数化
- 偏差値計算
カテゴリ変数化
選手名や会場のように数字で表現されていないものを数字に置き換えます。
どんな数字に置き換えるかを自分で決めたいときはmap関数、なんでもいい場合はscikit-learnのLabelEncoderを使いました。
#元データ df
import sklearn
#ラベルエンコード
list_LabelEncode = ['選手名','支部','天候','風向']
for label in list_LabelEncode:
le = sklearn.preprocessing.LabelEncoder()
le.fit(df[label])
df[label] = le.transform(df[label])
#map関数でのエンコード
place_code = {'桐生':'01','戸田':'02','江戸川':'03','平和島':'04','多摩川':'05','浜名湖':'06','蒲郡':'07','常滑':'08','津':'09','三国':'10','びわこ':'11','住之江':'12','尼崎':'13','鳴門':'14','丸亀':'15','児島':'16','宮島':'17','徳山':'18','下関':'19','若松':'20','芦屋':'21','福岡':'22','唐津':'23','大村':'24'}
class_mapping = {'B2':1,'B1':2,'A2':3,'A1':4}
df['会場'] = df['会場'].map(place_code)
df['級別'] = df['級別'].map(class_mapping)偏差値計算
レースの勝ち負けを左右するのは勝率などの数字が関係してきます。
ですが、単純に数字が良いから勝てるかと言われるとそうではありません。
大切なのはそのレースに出ている他の選手と比べて数字が良いのか悪いのかですよね。
なので、レースごとに勝率などのデータを偏差値にしました。
#元データ:df
# 艇番 選手名 全国勝率 全国2連率 当地勝率 当地2連率 モーター2連率 ボート2連率
#0 1 角浜 修 5.16 34.48 4.70 18.18 37.50 11.76
#1 2 冨田 祥 2.39 6.82 2.31 12.50 43.75 42.86
#2 3 深山祐二 4.42 27.10 4.53 22.50 13.33 20.00
#3 4 坂井康嗣 4.74 28.32 4.27 13.64 41.18 33.33
#4 5 吉川勇作 3.95 24.69 4.81 28.67 60.00 47.06
#5 6 大内裕樹 3.89 14.63 5.25 41.67 50.00 18.75
#偏差値に変える列名をリストで宣言
list_std = ['全国勝率','全国2連率','当地勝率','当地2連率','モーター2連率','ボート2連率']
#偏差値に変えてdfに戻す
for list in list_std:
df_std = df[list].astype(float)
win_mean=df_std.mean()
win_std=df_std.std()
if win_std==0: #もしdf_stdが同じ値だとwin_stdが0になってしまう
df[list]=50.0
else:
df[list] = df_std.apply(lambda x : ((x - win_mean)*10/win_std+50))
#偏差値計算後df
# 艇番 選手名 全国勝率 全国2連率 当地勝率 当地2連率 モーター2連率 ボート2連率
#0 1 角浜 修 61.106940 61.679264 53.759193 45.734662 47.791707 37.959259
#1 2 冨田 祥 32.308602 34.317736 30.623214 40.557927 51.780676 59.730599
#2 3 深山祐二 53.413521 54.378900 52.113538 49.671897 32.365568 43.727614
#3 4 坂井康嗣 56.740405 55.585735 49.596653 41.596919 50.140412 53.059188
#4 5 吉川勇作 48.527161 51.994905 54.824029 55.295217 62.151994 62.670780
#5 6 大内裕樹 47.903370 42.043460 59.083372 67.143378 55.769644 42.852560LightGBMでモデル作成
今回は目的変数を次のように設定してLightGBMで多クラス分類をしてみました。
| 着順 | 目的変数 |
| 1着 or 2着 | 0 |
| 3着 or 4着 | 1 |
| 5着 or 6着 | 2 |
モデルの作成には2021年8月1日から31日に開催されたレースデータを使いました。
回収率を計算
検証する日を指定し、その日のレースデータとオッズデータを取得します。
LightGBMで作成したモデルを使って、1レースごとに1〜3着の選手を予測して舟券を1点ずつ買ったと想定して的中率と回収率を計算しました。
舟券の買い方は以下の5つです。
- 単勝 → 1着を予想
- 2連複 → 1、2着を予想(順は問わない)
- 2連単 → 1、2着を予想(順番通り)
- 3連複 → 1、2、3着を予想(順は問わない)
- 3連単 → 1、2、3着を予想(順番通り)
2021年9月1日から7日までの1週間でそれぞれ計算したのを確認してみましょう。
9月1日
| 舟券の種類 | 的中率 | 回収率 |
|---|---|---|
| 単勝 | 51.67% | 86.58% |
| 2連複 | 35.83% | 99.42% |
| 2連単 | 28.33% | 110.33% |
| 3連複 | 20.83% | 75.83% |
| 3連単 | 9.17% | 103.17% |
9月2日
| 舟券の種類 | 的中率 | 回収率 |
|---|---|---|
| 単勝 | 50.83% | 88.08% |
| 2連複 | 30.83% | 99.08% |
| 2連単 | 18.33% | 105.92% |
| 3連複 | 24.17% | 89.75% |
| 3連単 | 10.83% | 130.75% |
9月3日
| 舟券の種類 | 的中率 | 回収率 |
|---|---|---|
| 単勝 | 48.48% | 141.74% |
| 2連複 | 27.27% | 169.17% |
| 2連単 | 18.18% | 257.88% |
| 3連複 | 21.21% | 154.77% |
| 3連単 | 9.09% | 346.52% |
9月4日
| 舟券の種類 | 的中率 | 回収率 |
|---|---|---|
| 単勝 | 44.44% | 80.28% |
| 2連複 | 25.69% | 71.53% |
| 2連単 | 17.36% | 63.68% |
| 3連複 | 27.78% | 101.11% |
| 3連単 | 6.94% | 67.78% |
9月5日
| 舟券の種類 | 的中率 | 回収率 |
|---|---|---|
| 単勝 | 55.36% | 99.70% |
| 2連複 | 26.79% | 80.30% |
| 2連単 | 19.05% | 70.18% |
| 3連複 | 19.64% | 73.99% |
| 3連単 | 7.14% | 65.18% |
9月6日
| 舟券の種類 | 的中率 | 回収率 |
|---|---|---|
| 単勝 | 56.82% | 98.33% |
| 2連複 | 33.33% | 100.30% |
| 2連単 | 25.00% | 111.44% |
| 3連複 | 28.79% | 115.53% |
| 3連単 | 15.15% | 167.95% |
9月7日
| 舟券の種類 | 的中率 | 回収率 |
|---|---|---|
| 単勝 | 62.12% | 97.65% |
| 2連複 | 42.42% | 114.09% |
| 2連単 | 28.79% | 102.65% |
| 3連複 | 25.76% | 95.45% |
| 3連単 | 9.09% | 87.80% |
正直言ってびっくりしました。
回収率のみグラフにするとこうなります。
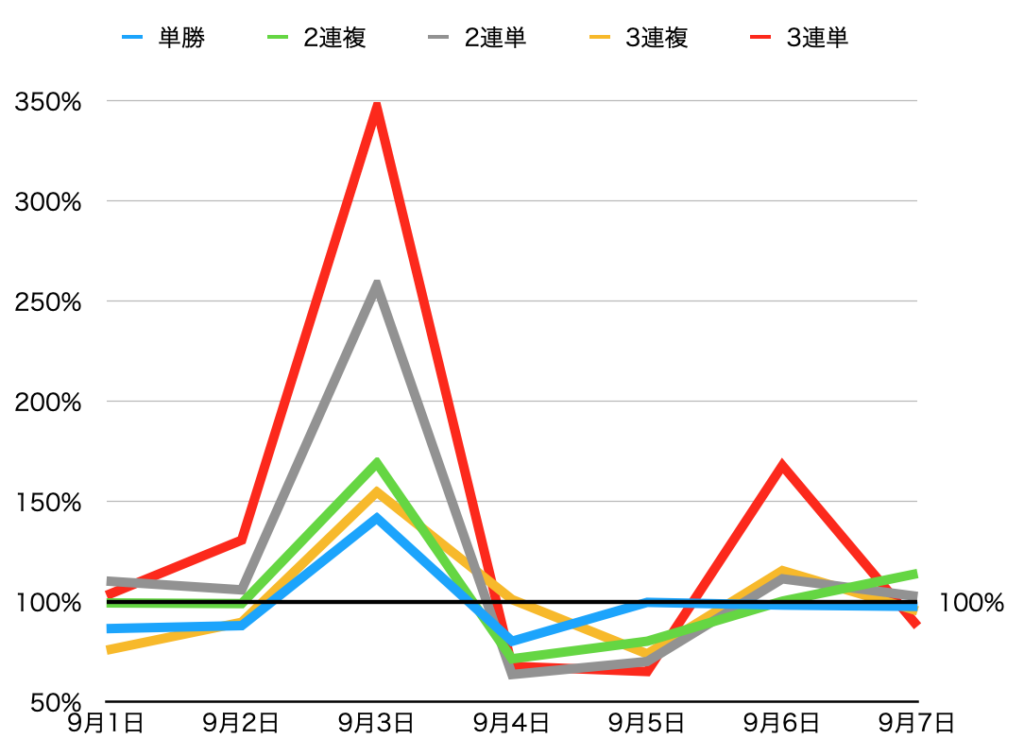
たまたまかもしれませんが、ほぼすべての日で回収率を100%超えを達成しました。
特徴量の重要度を確認
機械学習で作成したモデルのimportance(特徴量の重要度)を確認します。
要するに「着順を予想するのにどの特徴量を大切にすればいいのか」ってことですね。
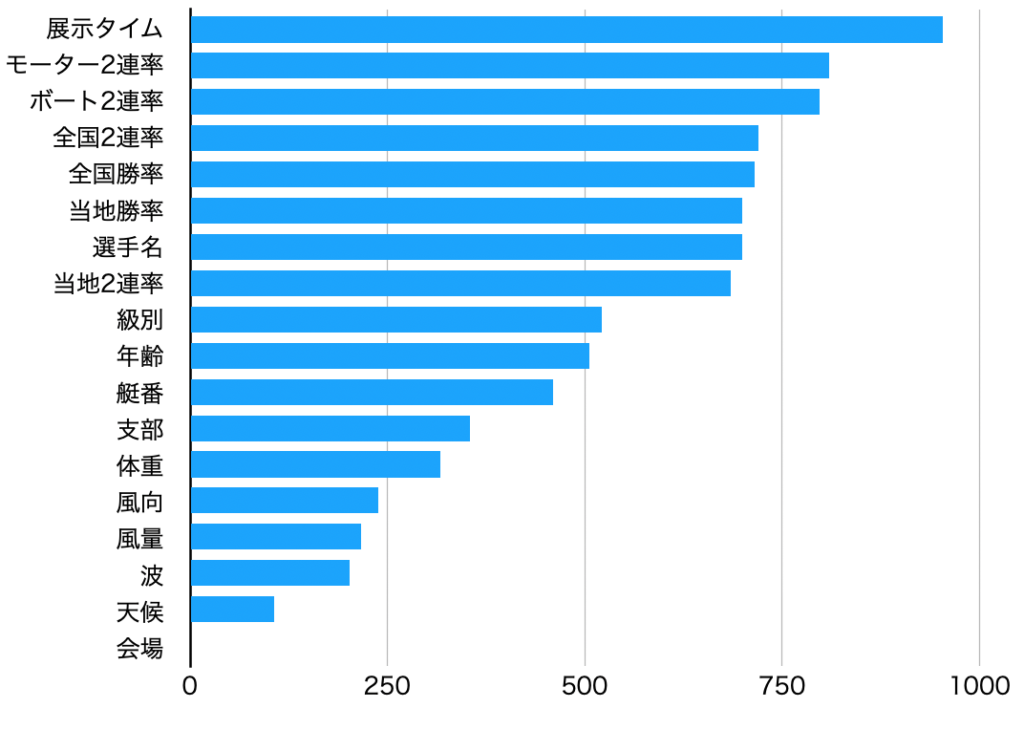
「展示タイム」「モーター2連率」「ボート2連率」の特徴量が大きいことがわかります。
反対に「風」や「波」などの環境条件やレースが開催されている「会場」は予測に影響をあたえていませんでした。
展示タイムはレース直前にわかる情報の1つなので、レース直前データをほかにも入れてみるといいかもしれませんね。k
なお、今回は単純に予想順位が高い選手から買いました。
「さらに買い方を機械学習すれば、回収率が上がるのでは?」と考えて検証した記事を載せておきます。
もしよければ読んでみてください。

まとめ
今回は競艇(ボートレース)で機械学習をして回収率を計算してみました。
3つのファイルをつくって行いました。
| Pythonファイル名 | 役割 |
|---|---|
| create_model.py | データ収集、データ前処理、機械学習でモデル作成 |
| inspection.py | データ収集、データ前処理、オッズデータ収集、モデルから回収率計算 |
| mymodule.py | 3つの関数を定義「データ収集」「データ前処理」「オッズデータ収集」 |
同じ作業部分を関数として定義する便利さにハマりそうですね。
「どうしてプログラミング上級者の人はすぐに関数にしたがるんだろう?」と不思議に思っていましたが、納得です笑
もしこれからプログラミングにチャレンジしたい人はいっしょに頑張りましょう。
ではまた。


コメント