
Pythonの機械学習を使って、株価が上がるかどうかの予想をしてみました。
これまで競馬、競艇の着順を機械学習して予想するってことをしてきたので、今回は株価にチャレンジです。
- 機械学習の流れを知りたい
- LightGBMの使い方を知りたい
という方にはオススメの内容となっています。
株価予想の全体図
まず、全体図をイメージしてみましょう。
今回の株価予想は「実際に株の売買をして儲かるか」という視点から考えています。
株価についての基礎知識
株価は需要と供給のバランスによって動き、リアルタイムで変化していきます。
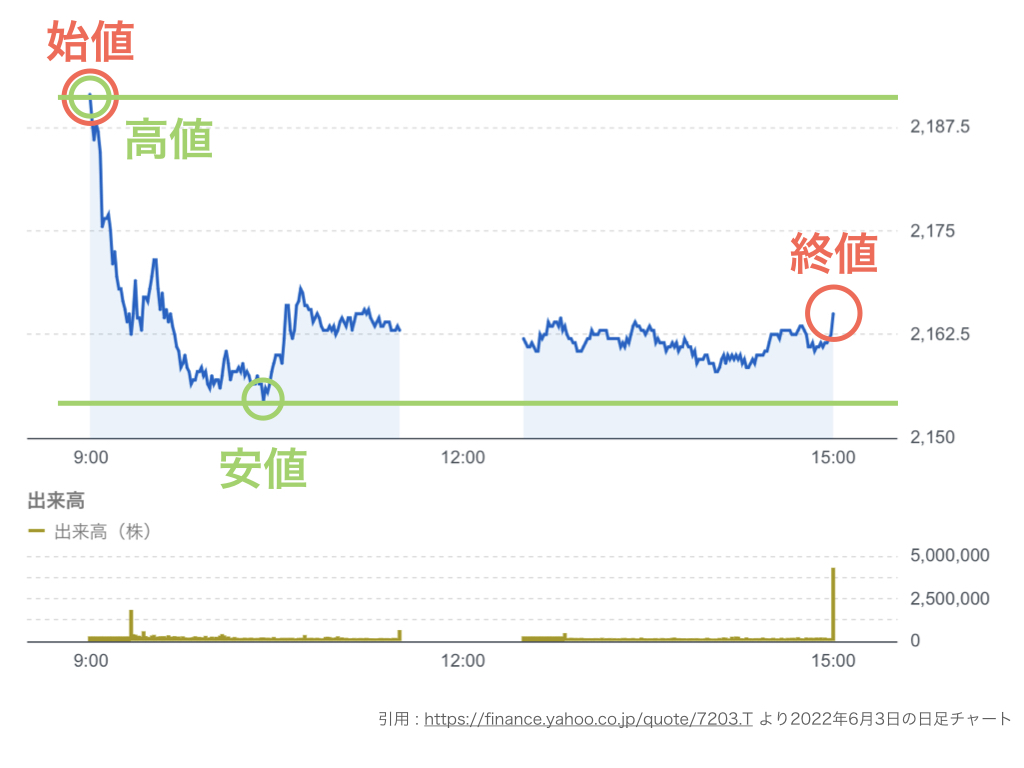
1日の間に株価がどのように値動きしたかはチャートを見ればわかるのですが、4つの値を使って表すこともあります。
- 始値 その日最初に取引された株価
- 高値 その日取引された値段のなかで1番高い株価
- 安値 その日取引された値段のなかで1番安い株価
- 終値 その日最後に取引された株価
さらに1日に売買された株数のことを出来高と言います。出来高は株価に先行すると言われていて、市場の活性度を測るバロメーターにもなっています。
基本的には株式市場は平日の日中しか取引できません。(ネット証券なら夜間でも取引できる場合も)
どうやって株を売買したと仮定するか?
今回は1日の取引が終わった夜、次の日の始値で買うかどうか決めます。
もし買った場合はその次の日の始値で売ります。
株を買うか決めるとき、過去1年分の株価データを学習に使うことにしました。
例えば、6月1日の夜に予想しプログラムが「買ったほうがいいよ!」と示した場合、買い注文して6月2日の始値で株を買います。
買った株は2日の夜、翌日6月3日の始値で売れるように売り注文を出すって感じです。
株取引するときは売買に手数料がかかるものですが、今回はわかりやすくするため、考えないこととします。
株価予想に使う株の銘柄はトヨタ自動車(7203)にします。
作業の流れ
Pythonを使ってこのような流れでやっていきます。
- データを集める(pandas-datareader)
- データの前処理をする
- 機械学習をしてモデルを作る
- モデルを使って予測する
順にやっていきましょう。
データ収集
データの収集にはpandasの拡張モジュールであるpandas-datareaderを使いました。
from pandas_datareader import data
#7203はトヨタ自動車の証券コード
df = data.DataReader('7203.T', 'yahoo', '2019-01-01', '2022-04-30')上のようにコードを書けば「yahooファイナンスから7203のトヨタ自動車の株価を2019年1月1日から2022年4月30日まで取得する」ことが可能です。
いつもスクレイピングに時間がかかるのでめちゃ助かりました笑
取得できたデータはこんな感じになっています。
| Date | High | Low | Open | Close | Volume | Adj Close |
| 2019-01-04 | 1272.0 | 1232.199951171880 | 1236.0 | 1269.199951171880 | 50059500.0 | 1160.423828125 |
| 2019-01-07 | 1324.4000244140600 | 1295.5999755859400 | 1299.0 | 1309.199951171880 | 38386000.0 | 1196.995849609380 |
| 2019-01-08 | 1337.4000244140600 | 1316.800048828130 | 1322.0 | 1325.199951171880 | 39896500.0 | 1211.62451171875 |
| 2019-01-09 | 1343.0 | 1325.800048828130 | 1342.4000244140600 | 1335.4000244140600 | 27472000.0 | 1220.950439453130 |
| 2019-01-10 | 1342.800048828130 | 1325.4000244140600 | 1326.0 | 1340.800048828130 | 31702000.0 | 1225.8875732421900 |
- Date(index) → 日付
- High → 高値
- Low → 安値
- Open → 始値
- Close → 終値
- Volume → 出来高
- Adj Close → 調整後終値
その日の取引が終わって終値が確定したあと、さらに調整が入って終値が変わることがあるそうです。
今回は調整されたあとの終値(Adj Close)を終値として使うことにしました。
データの前処理
機械学習するためにデータを加工していきます。
特徴量(予想に使う項目)はさきほどpandas_datareaderで取得した高値、安値、始値、終値、出来高の5つでは物足りないので、「終値と始値の差」を当日、前日、前々日分追加しました。
終値と始値の差は、そのときの株価によって影響が変わってきます。
たとえば100円から110円になるのと、10000円から10010円になるのでは同じ10円アップでもスケールが違いますよね。
なので、(終値 – 始値)/ 始値 で求めます。
目的変数(予想する項目)は翌日と翌々日の始値の差に設定しました。
翌々日から翌日を引き、プラスかどうかで次のように変数を決めます。
- プラス(買ったら利益) → 「1」
- マイナス(買ったら損) → 「0」
さらに今回は「1年間売り買いした結果、どのくらいのリターンが出るのか」知りたいので、検証用にデータフレームをもう1つつくっておきます。
もし、その日に買ったとして、何円で買い、何円で売ることになるのかをまとめておくと便利だからです。
前日のデータや翌日のデータを使うとき、shift関数が便利でした。
shift(1)で「下に1つずらす」、shift(-1)で「上に1つずらす」ことができます。
#翌日の始値
df['Open1'] = df['Open'].shift(-1)
#翌々日の始値
df['Open2'] = df['Open'].shift(-2)
#目的変数
df['Target'] = df['Open2'] - df['Open1']こんな感じで、カンタンに目的変数を設定できました。
今回のプログラムで1番勉強になったところです。
特徴量のデータをX、目的変数のデータをyとわけ、いよいよ機械学習に入っていきます。
LightGBMで機械学習
Pythonなら機械学習は数行でできてしまいます。
さすがPython。
import lightgbm as lgb
#モデルを宣言
model = lgb.LGBMClassifier()
#学習してモデルを作成
model.fit(X_train, y_train)
#モデルを使って0の確率と1の確率を計算
prob = model.predict_proba(X_test)X_train、y_trainはそれぞれ検証する日から過去1年間のデータですね。
過去1年のデータで学習してモデルをつくり、X_testという検証する日の特徴量のデータで予想したらどうなるかを見るわけです。
probは、X_testで予想したときの「0」「1」になる確率を表しています。
今回は「1」(プラス)になる確率が0.5以上のときは買い、0.5以下のときは買わないという流れにしました。
買ったり売ったりするときは、リアルの株取引と同じように100株単位で行います。
モデルを使って株価が上がるか予想する
1年間、売り買いした結果
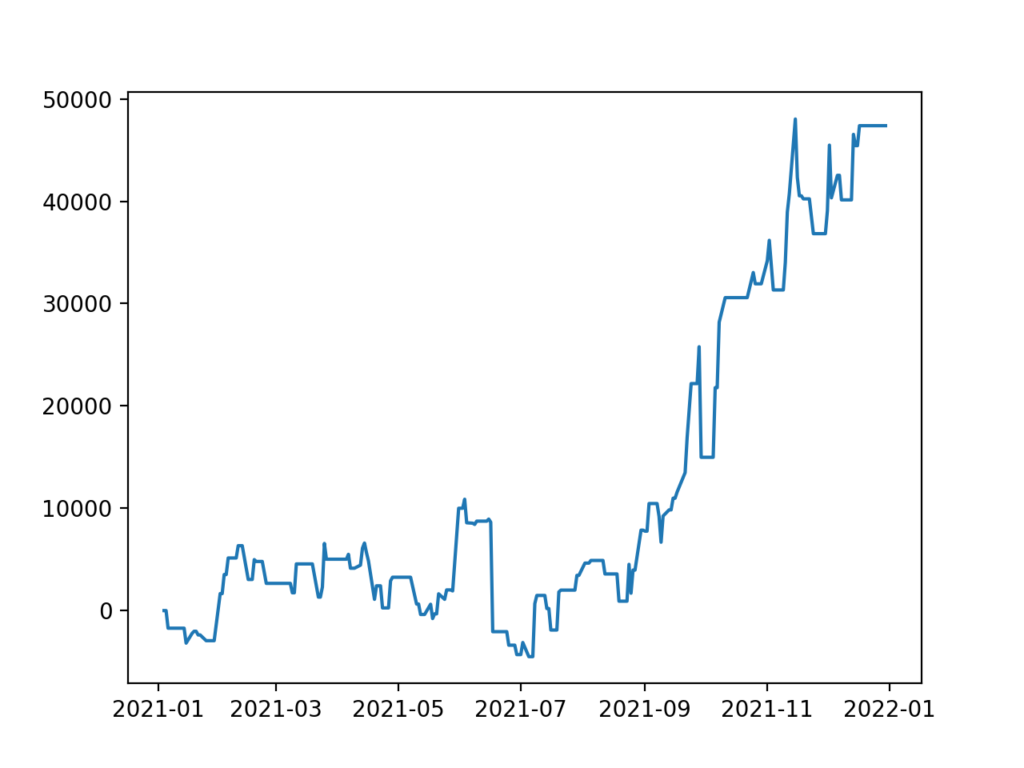
2021年の1年間で売り買いをした結果がこちらです。
| 取引可能日数 | 買った日数 | 買った金額 | 売った金額 | 収支 | リターン | |
| 1月 | 19 | 6 | 925,120 | 922,180 | -2,940 | -3.18 |
| 2月 | 18 | 9 | 1,450,220 | 1,455,820 | 5,600 | +3.86 |
| 3月 | 23 | 6 | 993,440 | 995,800 | 2,360 | +2.38 |
| 4月 | 21 | 12 | 2,023,980 | 2,022,220 | -1,760 | -0.87 |
| 5月 | 18 | 10 | 1,757,740 | 1,764,480 | 6,740 | +3.83 |
| 6月 | 22 | 10 | 1,988,040 | 1,973,740 | -14,300 | -7.19 |
| 7月 | 20 | 9 | 1,760,240 | 1,767,980 | 7,740 | +4.40 |
| 8月 | 21 | 8 | 1,539,520 | 1,543,940 | 4,420 | +2.87 |
| 9月 | 20 | 13 | 2,586,860 | 2,593,980 | 7,120 | +2.75 |
| 10月 | 21 | 5 | 974,850 | 991,800 | 16,950 | +17.39 |
| 11月 | 20 | 11 | 2,305,650 | 2,310,550 | 4,900 | +2.13 |
| 12月 | 22 | 8 | 1,664,700 | 1,675,250 | 10,550 | +6.34 |
| 合計 | 245 | 107 | 19,970,360 | 20,017,740 | 47,380 | +2.37 |
なんとなんと、プラスでした笑
正直言って「始値や終値だけで予想して当たるわけないか」くらいで思っていたのでびっくりです。
収支の流れがわかるようにグラフも入れておきます。
特徴量の重要度の確認
モデルにおける特徴量の重要度を確認しておきます。
つまり「株価が上がるかどうか判断するのに、どの項目が大切か」がわかるんですね。
重要度をグラフにしたものがこちらです。
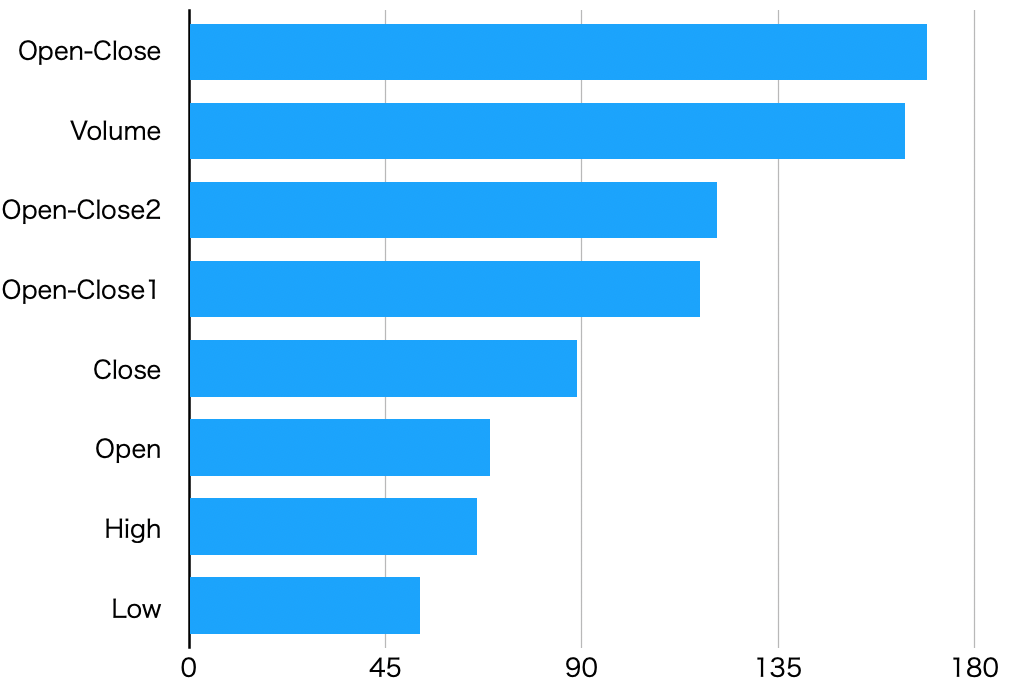
グラフを見ると、終値と始値の差がかなり重要みたいです。
(Open-Close1は前日、Open-Close2は前々日のもの)
そして、同じくらい出来高も大切みたいですね。
出来高は取引量みたいなものなので、「その日全体としては株価が上昇しており、出来高が多いときはしばらく上昇傾向にある」と言えるでしょう。
ただし、ひとつ大事なことを忘れてはいけません。
さきほども書いたことですが、取引手数料を考えていないという点です。
買った日数が107ということは107×2の214回の手数料がかかるはず。
(取引手数料は基本的に買うときも売るときもかかります)
214回分の手数料を考えてしまうと、ほぼほぼ儲けはないのかなって感じですね。
それだけ資産運用の手数料はコワイってこと(何の話?)
とはいえ、機械学習は成功と言えそうですね。
まとめ
今回はPythonを使って株価が上がるか予想してみました。
機械学習にはLightGBMを使用しました。
2021年1年間の予想結果は47,380円の利益(+2.36%)。
大勝ちとまではいかなくてもじゅうぶん勝利です。
特徴量や機械学習の手法を調整すればもっと良くなる気がしています。
もっと勉強してチャレンジしていきたいですね。
今回のチャレンジで1番驚いたのはpandas-datareaderの便利さ。
たった1行のコードでカンタンに株価データが取得できるとは思いませんでした。
これまで競馬や競艇でも機械学習にチャレンジしてきましたが、データの取得に時間がかなりかかっていたので「こんなカンタンにデータとれちゃっていいいの?」って感じです。
まだPythonで機械学習したことない方には、pandas-datareaderの株価データはかなりオススメです。
これからもがんばっていきましょう。
ではまた。

コメント